NVIDIA Triton Inference Server Intro
NVIDIA Triton Inference Server (이하 Triton)는 NVIDIA에서 개발한 오픈 소스 AI 모델 추론 전용 서버 소프트웨어
- 간단히 말해, 학습이 완료된 AI 모델을 실제 서비스(운영 환경)에 쉽게 배포 해주고, 클라이언트의 요청에 따라 결과를 출력(추론)해주는 역할
- 특정 프레임워크나 하드웨어에 종속되지 않고 범용적으로 사용할 수 있다는 것이 가장 큰 특징
- *추론(Inference) : 학습된 모델이 실제 데이터를 입력받아 결과를 내놓는 과정
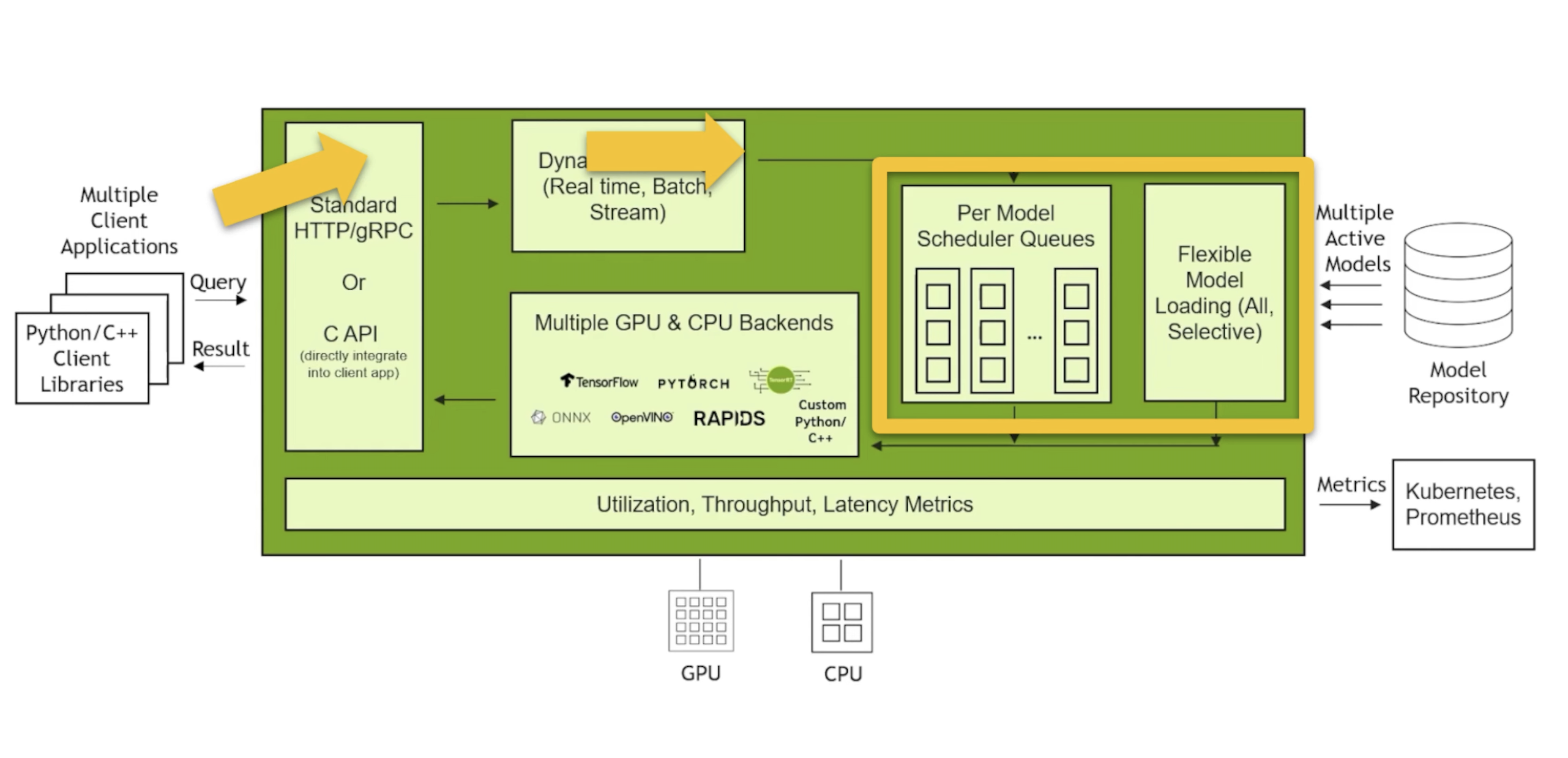
1. 주요 특징 및 장점
- 다양한 프레임워크 지원 (Framework Agnostic): PyTorch, TensorFlow, ONNX, TensorRT, OpenVINO는 물론 Python 기반의 커스텀 코드(Scikit-learn 등)까지 한 서버에서 동시에 돌릴 수 있습니다.
- 고성능 최적화:
- 다이나믹 배칭(Dynamic Batching): 여러 클라이언트의 개별 요청을 서버에서 자동으로 묶어 처리함으로써 GPU/CPU 활용도를 극대화하고 처리량을 늘립니다.
- 병렬 모델 실행 (Concurrent Model Execution): 하나의 GPU에서 여러 모델을 동시에 실행하거나, 동일 모델의 인스턴스를 여러 개 띄워 성능을 높입니다.
- NVIDIA GPU뿐만 아니라 x86/ARM CPU 환경에서도 동작하며, 클라우드(AWS, GCP, Azure), 온프레미스, 엣지 기기까지 배포가 가능합니다.
- HTTP/REST 및 gRPC 프로토콜을 지원하며, Kubernetes(KServe, Kubeflow)와 쉽게 통합됩니다.
- 서버 재시작 없이 모델을 실시간으로 로드/언로드하거나 버전을 관리(A/B 테스트 등)할 수 있습니다.
- Docker file 지원으로 CI/CD 파이프라인 결합 용이.
2. Triton의 핵심 아키텍처
Triton은 크게 세 가지 영역으로 나뉩니다.
- Model Repository: 서버가 실행될 때 읽어올 모델 파일과 설정값(
config.pbtxt)이 저장된 디렉토리입니다. - Server Core: 클라이언트 요청을 받고, 적절한 모델 스케줄러(Stateless, Stateful, Ensemble 등)로 전달하는 핵심 엔진입니다.
- Backends: 실제 모델을 구동하는 엔진(PyTorch, TensorFlow 등)으로, 코어와 분리되어 있어 확장이 쉽습니다.
Q,Triton은 Apple Chip의 뉴럴엔진을 사용하는가?
- 아니다, Triton은 이름에서 알 수 있듯이 NVIDIA GPU(CUDA) 환경에 최적화된 서버.
- 뉴럴 엔진은 Core ML이라는 애플 전용 프레임워크를 통해 최적화되었을 때 가장 강력.
- Triton은 이를 지원하지 않는다.
3. Quick Start
Reference Docker Version : https://docs.nvidia.com/deeplearning/triton-inference-server/release-notes/rel-25-12.html#rel-25-12
# 디렉터리 이동
cd Quick_Start
# 예제 모델 다운로드
fetch_models.sh
# 이미지 다운로드
docker pull nvcr.io/nvidia/tritonserver:25.12-py3
# docker container up
docker run --rm \
-p 8000:8000 -p 8001:8001 -p 8002:8002 \
-v ./model_repository:/models \
nvcr.io/nvidia/tritonserver:25.12-py3 \
tritonserver --model-repository=/models
# Check Logs
I0122 12:01:38.001149 1 grpc_server.cc:2562] "Started GRPCInferenceService at 0.0.0.0:8001"
I0122 12:01:38.001294 1 http_server.cc:4815] "Started HTTPService at 0.0.0.0:8000"
I0122 12:01:38.055684 1 http_server.cc:358] "Started Metrics Service at 0.0.0.0:8002"
# Check health check
curl -v localhost:8000/v2/health/ready
* Host localhost:8000 was resolved.
* IPv6: ::1
* IPv4: 127.0.0.1
* Trying [::1]:8000...
* Connected to localhost (::1) port 8000
> GET /v2/health/ready HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/8.7.1
> Accept: */*
>
* Request completely sent off
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host localhost left intact
---
# densenet_onnx 모델의 입력/출력 구조 확인
curl localhost:8000/v2/models/densenet_onnx/config
{"name":"densenet_onnx","platform":"onnxruntime_onnx","backend":"onnxruntime","runtime":"","version_policy":{"latest":{"num_versions":1}},"max_batch_size":0,"input":[{"name":"data_0","data_type":"TYPE_FP32","format":"FORMAT_NONE","dims":[1,3,224,224],"is_shape_tensor":false,"allow_ragged_batch":false,"optional":false,"is_non_linear_format_io":false}],"output":[{"name":"fc6_1","data_type":"TYPE_FP32","dims":[1,1000,1,1],"label_filename":"","is_shape_tensor":false,"is_non_linear_format_io":false}],"batch_input":[],"batch_output":[],"optimization":{"priority":"PRIORITY_DEFAULT","input_pinned_memory":{"enable":true},"output_pinned_memory":{"enable":true},"gather_kernel_buffer_threshold":0,"eager_batching":false},"instance_group":[{"name":"densenet_onnx","kind":"KIND_CPU","count":2,"gpus":[],"secondary_devices":[],"profile":[],"passive":false,"host_policy":""}],"default_model_filename":"model.onnx","cc_model_filenames":{},"metric_tags":{},"parameters":{},"model_warmup":[]}%
4. 정리
- 추론 요청은 gRPC, HTTP 또는 C API를 통해 Triton으로 보낼 수 있으며, 기본적으로 순차적으로 처리되지만 성능 향상을 위해 일괄 처리될 수 있습니다.
- 각 모델은 추론 요청 대기열을 관리하는 자체 스케줄러를 가집니다.
- 모델은 서버 재시작 없이 클라우드 스토리지 또는 로컬 파일 시스템에서 동적으로 로드될 수 있습니다.
- 스케줄러는 요청을 적절한 프레임워크 백엔드로 보내 실제 계산을 수행하고, 출력 텐서는 클라이언트로 다시 전송됩니다.
- 고급 기능 : Dynamic Batching, Launches tow instances per GPU, TensorRT EP acceleration on ONNX Runtime backend, Ensemble of model
- Model Analyzer : https://github.com/triton-inference-server/model_analyzer
- Triton Model Analyzer는 Triton 추론 서버 에서 실행되는 단일, 다중, 앙상블 또는 BLS 모델에 대해 특정 하드웨어 환경에서 최적의 구성을 찾는 데 도움을 주는 CLI 도구입니다 . Model Analyzer는 또한 다양한 구성의 장단점과 각 구성에 필요한 컴퓨팅 및 메모리 요구 사항을 더 잘 이해할 수 있도록 보고서를 생성합니다.
- Model Navigator : https://github.com/orgs/triton-inference-server/repositories?q=navigator
- Triton Model Navigator는 PyTorch, TensorFlow 또는 ONNX로 구현된 모델 및 파이프라인을 TensorRT로 전환하는 과정을 효율적으로 간소화.
- TensorRT: NVIDIA에서 제공하는 고성능 딥러닝 추론 최적화 엔진입니다. PyTorch나 TensorFlow 모델을 이 형식으로 변환하면 GPU에서 훨씬 빠르게 작동합니다.
- TensorFlow 에서 Tensor의 의미? 다차원 배열(Multi-dimensional Array) 데이터를 담는 컨테이너, GPU라는 하드웨어가 데이터를 처리하는 물리적인 방식과 완벽하게 맞물려 있음.
- Triton Model Navigator는 PyTorch, TensorFlow 또는 ONNX로 구현된 모델 및 파이프라인을 TensorRT로 전환하는 과정을 효율적으로 간소화.
Ref