4장 AI 시스템 평가하기
_4.1 평가 기준
__4.1.1 도메인 특화 능력
__4.1.2 생성 능력
__4.1.3 지시 수행 능력
__4.1.4 비용과 지연 시간
_4.2 모델 선택
__4.2.1 모델 선택 과정
__4.2.2 모델 자체 개발 대 상용 모델 구매
__4.2.3 공개 벤치마크 탐색하기
_4.3 평가 파이프라인 설계하기
목적 : 개방형 질문에대한 평가 파이프라인 설계하기
- *개방형 질문 = 딱 답이 정해져 있는것이 아닌, 서술형이며 정답이 주관적인 것.
1단계: 시스템의 모든 구성 요소 평가하기
1-1, 시스템의 각 프로세스마다 분리하여 평가해야 한다.
- eg, 지원자의 주소지 파악 : pdf 추출 -> pdf 텍스트 변환 -> 텍스트에서 주소지 파악.
- End-to-End 평가 보다는 3단계로 분리하여 각 구성요소 개별 평가 --> 문제 발생 위치 찾기 좋음
1-2, 평가 방법은 크게 2가지 - Turn-based evaluation 각 개발 응답 품질 평가
- Task-based evaluation 작업 완료 여부 평가
- eg, BIG-bench (Beyond the Imitation Game Benchmark)
- BIG-bench = 대형 언어모델 능력을 평가하기 위해 만든 대규모 개방형 벤치마크.
- 평가 영역, 논리 추론, 수학 문제, 상식 추론, 코드 이해, 창의적 언어 생성, 게임 전략
2단계: 평가 가이드라인 만들기
2-1. 평가 방법 선택
평가 방법은 여러 종류가 있음
| 목적 | 방법 |
|---|---|
| 유해성 감지 | 분류기 |
| 질문 관련성 | semantic similarity |
| 사실 일관성 | AI evaluator |
| 품질 평가 | human evaluator |
2-2, 평가 비용 최적화 전략
평가 방법 혼합
100% 데이터 → 저가 classifier (저렴이 모델)
1% 데이터 → 고품질 AI evaluator (비싼 모델) * 비용 절감 * 신뢰도 확보
2-3, 평가 지표를 비즈니스 지표와 연결하기
- 예) 고객 센터 챗봇 : 사실 일관성 90% (평가지표) -> 고객 지원 요청의 50% 자동화 (비즈니스 지표)
- 유용성 임계값 -> eg, 일관성이 50% 이상은 되어야 적어도 쓸모는 있다.
3단계: 평가 방법과 데이터 정의하기
AI 평가에서 주석(annotation)은 보통 정답 라벨(label) 를 의미한다.
- annotation은 추후 파인튜닝에 사용 된다.
- 가능하면 데이터 슬라이싱(하위 집합) 후 라벨링을 한다.
- 편향 축소, 디버깅, 애플리케이션 개선 영역 발굴, 심슨의 역설 회피
- 평가 결과에 대한 95% 신뢰도를 가지는데 필요한 표본 데이터는 아래 케이스 별로 다르다.
- 30% 더 개선되었음을 감지하기 위해 10개의 데이터셋 필요
- 3% 더 개선 = 1,000개 데이터 셋 필요
- 1% 더 개선 = 10,000개 데이터 셋 필요
- *즉,프롬프트 잘 작성해서 50% -> 80%으로 올리는 것 보다, 95% 에서 96% 개선됨을 증명하기가 더 극단적으로 어려워진다.
- 로그 프롭(퍼플렉시티)을 사용하면 좋다. 특히 분류 작업에 대해.
🌿 *심슨의 역설 (Simpson’s Paradox)
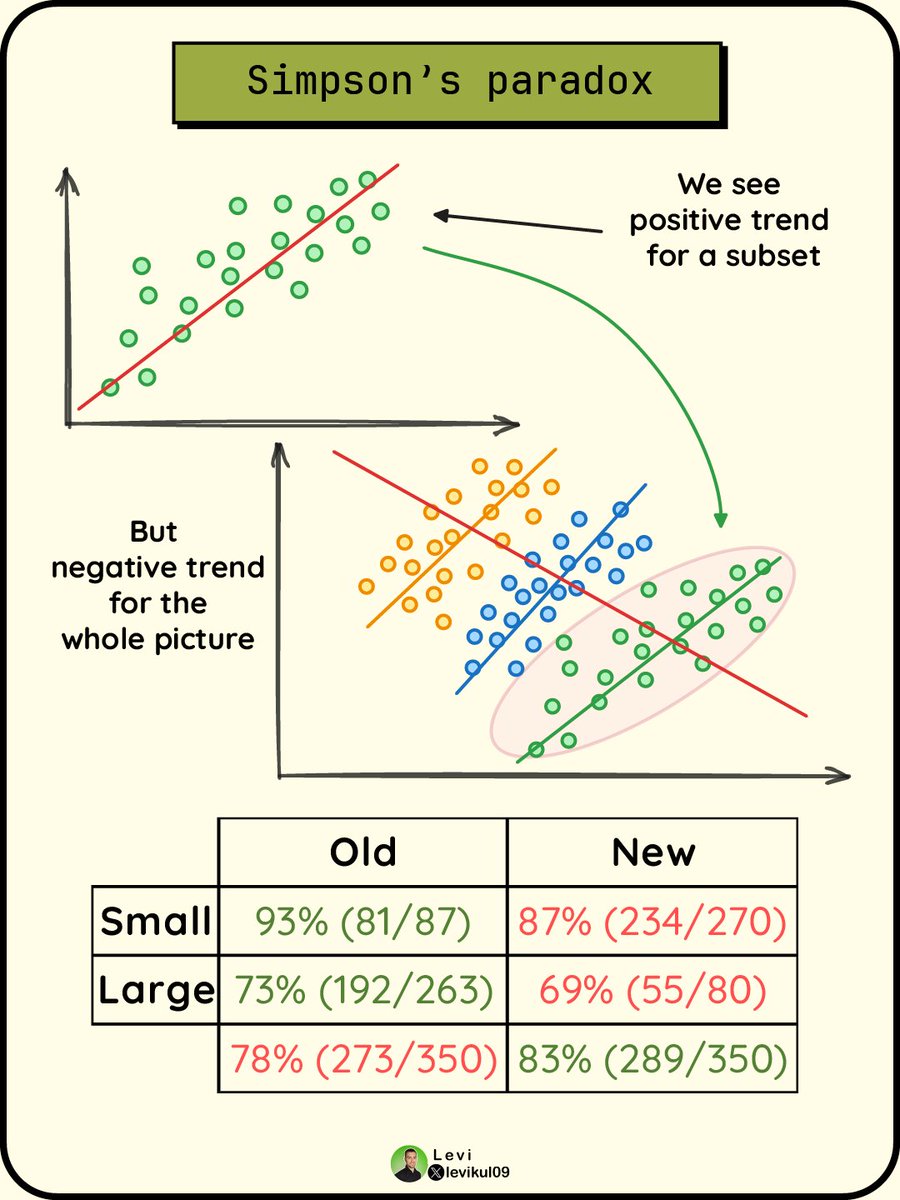
- 심슨의 역설 = 데이터를 전체로 보면 한 결과가 나오는데, 집단을 나누어 보면 반대 결과가 나타나는 현상.즉 * 전체 데이터 결론 ≠ 그룹별 데이터 결론
직관적 예시 - 대학 합격률 예시
전체 데이터
| 성별 | 합격률 |
|---|---|
| 남성 | 60% |
| 여성 | 40% |
→ 결론 * 남성이 더 많이 합격
하지만 학과별로 보면
| 학과 | 남성 합격률 | 여성 합격률 |
|---|---|---|
| A (어려움) | 30% | 35% |
| B (쉬움) | 80% | 85% |
→ 결론 * 여성이 두 학과 모두 더 높음
그런데 전체 결과는 왜 반대일까?
- 여성 지원자 대부분 → 합격률 낮은 학과
- 남성 지원자 대부분 → 합격률 높은 학과
→ 그래서 전체 평균이 뒤집힘.
🌿 평가 파이프라인 평가하기
- 1, 실제 평가지표개선이 비즈니스 지표 개선으로 이어지는가?
- 2, 평가 파이프라인은 신뢰 가능한가? (AI 평가자는 온도 파라미터를 = 0으로) 반복해도 같은 결과냐?
- 3, 평가 파이프라인 때문에 어플리케이션 전체 비용이 얼마나 더 증가하나?