개발자와 협업을 위한 kafka의 핵심 개념 1
카프카 소개
문제 정의
기업의 MSA 환경에서는 수많은 서버들이 존재한다.
- 서버간 데이터를 주고 받을때 간단한 시스템이면 쉽다.
- 하지만 수십개의 시스템이 서로 엉킨 상태로 데이터의 흐름이 발생하는 시스템이라고 생각해보면
- 매우 복잡하고, 유지 비용이 기하급수적으로 증가한다.
데이터를 주고받는 프로토콜도 매우 다양하다.
- TCP, HTTP, REST, FTP, RPC, JDBC 등등
데이터를 보내는 포멧도 매우 다양하다.
- 바이너리, CSV, JSON, XML, protobuf
특히나 데이터 스키마가 변경되면 , 이에 의존하고 있는 서버들까지 장애가 번질 수 있음
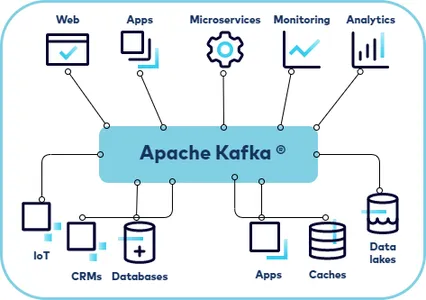
해결 (카프카)
카프카라는 컴포넌트로 서버간에 디커플링을 도입한다.
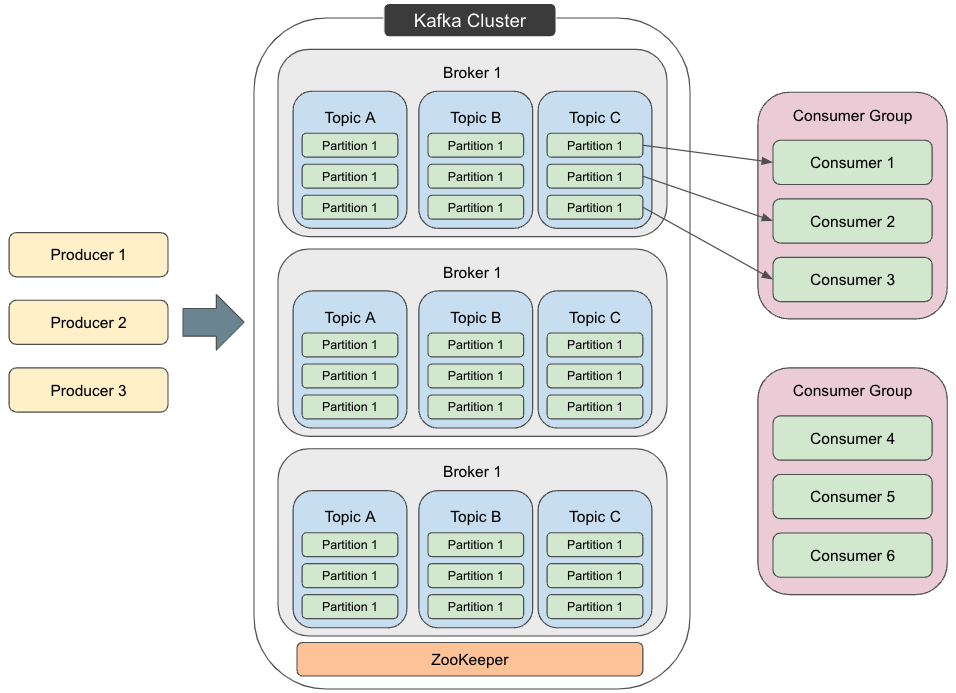
- 카프카는 링크드인에서 만든 오픈소스입니다.
- 분산 환경에서 복원력이 뛰어나며, 장애를 허용하는 아키텍처입니다.
- 수평 확장성이 좋습니다.
- 메시지 브로커의 수를 늘릴 수 있습니다.
- 초당 수백만 건의 메시지 전달이 가능합니다.
- 실시간으로 고성능 메시지 전달이 가능하며, 레이턴시는 10ms 미만입니다.
비동기 vs 동기식 처리
동기식 처리
- REST API : 서버로 요청했다가 반드시 응답을 기다린다.
비동기식 처리
- 요청을 보내고, 추후 완료여부 체크.
- Pub/Sub, MessageQueue
메세지 브로커
- MessageQueue 구현
- Redis : 빠른 실시간 처리, 내구성이 덜 중요.
- Kafka : 높은 내구성, 여러 소비자.
- *Kafka, Redis PubSub 는 서버(언어) 영향을 받지 않는다.
- *Redis는 특정 라이브러리에 종속될 수 있다.( python - celery, node.js - bull.js )
usecase 및 사례
사용 사례
- 메시징 시스템
- 유저 활성화 추적
- 다른 지역의 메트릭 수집
- 애플리케이션 로그 수집
특징
- 스트림 프로세싱
- 시스템 간 디커플링
- 스파크, 하둡 등 많은 빅데이터 플랫폼과 통합 가능
- pub/sub 마이크로서비스
실제 사례
- 넷플릭스: 유저가 영상 시청 중 실시간으로 다음 추천 영상 업데이트 서비스
- 우버: 사용자, 택시, 여행 데이터를 실시간 수집 및 수요 예측 서비스
- 링크드인: 스팸 방지 서비스, 사용자 상호작용 데이터 수집으로 관계 추천 서비스